8B 干翻了 32B:Granite 4.1 告诉我,大力不一定出奇迹
今天读到 IBM 发了一篇技术博客,讲他们新出的 Granite 4.1 模型。看完之后我坐那儿发了会儿呆。
不是因为它有多震撼——说实话,大模型圈子里「又发新模型」这种事已经不怎么刺激我了。让我愣住的是一个数字对比:
8B 的密集模型,匹敌甚至超越了 32B 的 MoE 模型。
上一次看到 IBM 的 Granite 4.0-H-Small,是个 32B 参数、激活 9B 的混合专家模型。当时觉得,嚯,这架构设计得挺精巧。结果 Granite 4.1 用一个朴素的 8B 密集架构,在 IFEval、MMLU-Pro、GSM8K、DeepMind-Math、ArenaHard 等十几个基准上,全面追平或反超。
参数少了四倍,效果没掉,反而涨了。
这事儿值得想。
他们做了什么
Section titled “他们做了什么”Granite 4.1 的训练分三大块:预训练、监督微调、强化学习。每一块都不算新东西,但每一块都做得极其较真。
预训练用了五个阶段,15 万亿 token。不是往一个池子里倒数据然后开跑,而是一步步换配方:

第一阶段,10 万亿 token,什么都有——网页、代码、数学、技术文档、多语言,大杂烩。这个阶段打基础。
第二阶段,2 万亿 token,数学从 7% 拉到 35%,代码从 20% 拉到 30%。通用能力有了,开始专攻推理。
第三、四阶段,叫「高质量数据退火」。这个词有意思——退火,冶金里的概念,慢慢降温让晶体结构更完美。他们也是这个意思:数据量越来越少(2T → 0.5T),但质量越来越高。
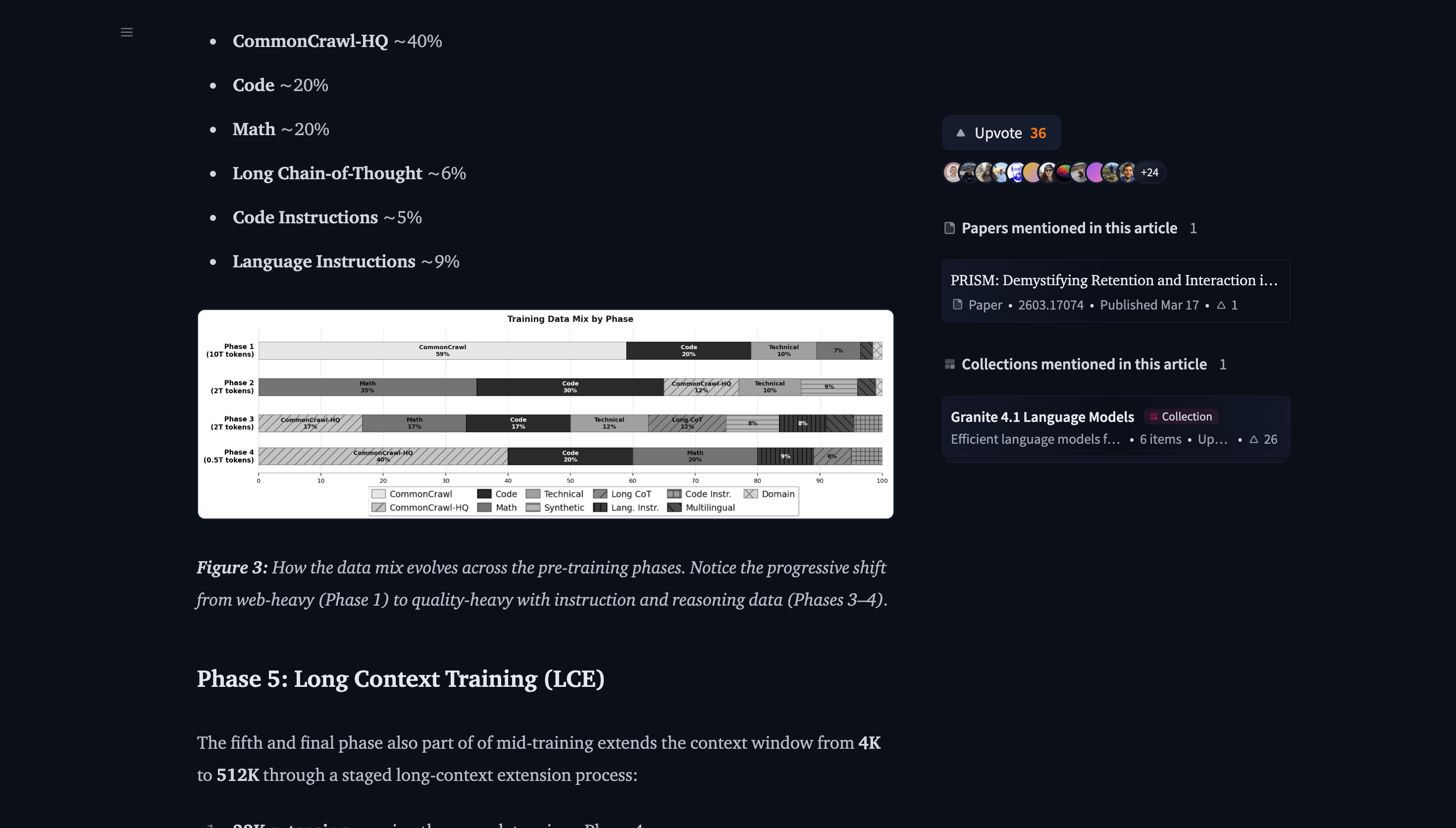
CommonCrawl 的高质量子集占比从 16% 涨到 40%。还掺进了长链式推理数据和指令微调数据。
第五阶段,把上下文窗口从 4K 一路拉到 512K。用 80% 的书籍数据加 20% 的代码仓库数据做最后的长上下文训练。
然后监督微调,约 410 万条样本。关键是他们用了一个 LLM-as-Judge 的框架来筛选数据——六个维度打分,幻觉、错误前提、错误计算直接一票否决。

不是所有数据都值得喂给模型,有些数据喂了反而有害。
最后是多阶段强化学习,分四步走:多领域 RL → RLHF → 身份与知识校准 → 数学 RL。每一步都有讲究——比如 RLHF 会拉低数学能力,所以最后再加一步数学 RL 把分数补回来,GSM8K 涨了将近 4 分,DeepMind-Math 涨了 23 分。

话说回来,这些技术细节单独拎出来,哪一条都不算革命性。五阶段预训练?别人也在做。LLM-as-Judge 筛数据?不新鲜。多阶段 RL?DeepSeek 早就玩过了。
那为什么效果好?
我觉得答案不在某一个环节,而在所有环节的叠加。
就像做饭。食材还是那些食材,但你洗得干净、切得均匀、火候掐得准、调味有先后——同样的原料,出来的味道就是不一样。
Granite 4.1 的核心信息不是「我们发明了什么新技术」,而是「我们把已知的事情做到了极致」。
这意味着什么
Section titled “这意味着什么”过去几年大模型圈子的叙事是:参数越大越好,架构越复杂越好。MoE 火起来就是因为它能用更少的激活参数实现更大的总参数量——听起来像是白嫖。
Granite 4.1 给了这个叙事一巴掌。
一个 8B 的密集模型,训练得当,可以干翻 32B 的 MoE。这意味着什么?
意味着模型能力的瓶颈不在架构,在训练的质量。
你不需要更聪明的架构设计,你需要更干净的数据、更精细的阶段划分、更严格的过滤、更有针对性的强化学习。这些东西不性感,没有论文标题好听,但它们才是真正拉开差距的东西。
就像两个人健身。一个天天换训练计划,今天 CrossFit 明天普拉提后天举重,追求最新最潮的方法。另一个就练深蹲、硬拉、卧推,但动作标准、组数到位、饮食跟上、睡眠充足。半年后看,赢的是后者。
Granite 4.1 就是那个练基础动作的人。


看看上面这两张图——在工具调用和指令遵循上,8B 模型(最下面那条线)已经非常接近甚至在某些点上超过了上一代 32B MoE 模型。这不是运气,是训练质量的直接体现。

这张对比图更直观——深蓝色是 Granite 4.1-8B,浅蓝色是 Granite 4.0-H-Small (32B-A9B)。在 IFEval、AlpacaEval、MMLU-Pro、BBH、GSM8K、DeepMind-Math、ArenaHard、BFCL、MBPP 上,8B 全部追平或反超。

30B、8B、3B 三个尺寸,性能随模型大小可预测地增长。这说明训练方法是通用的,不是只在一个尺寸上碰巧有效。
还有一个细节让我在意
Section titled “还有一个细节让我在意”他们发的是 Apache 2.0 许可证。完全开源。
不是那种「你可以看但不能商用」的半开源,也不是「需要申请审批」的伪开源。就是 Apache 2.0,随便用,随便改,随便部署。
在当下这个越来越封闭的大模型环境里,这种开放态度本身就值得尊重。
8B 干翻 32B,这件事本身会过时。明年可能就有 4B 干翻 8B 的。但背后的道理不会过时:
质量大于体量。认真大于聪明。
把已知的事情做到极致,比追逐新技术更有力量。
你觉得呢?在你们团队里,是追求最新技术的人跑得快,还是把基础做到位的人跑得快?
Granite Team, IBM. Granite 4.1 LLMs: How They’re Built. Hugging Face Blog. https://huggingface.co/blog/ibm-granite/granite-4-1