笔记本上的21GB模型,画鹈鹕赢了最贵的闭源旗舰

昨天刷到一条博客,作者叫 Simon Willison。搞 Django 的那哥们,写了二十年技术博客,日更。他搞了个测试:让 AI 画一只”骑自行车的鹈鹕”——纯 SVG,看谁画得像样。这测试从 2024 年 10 月开始,跑了 34 个模型,一直有个规律:鹈鹕画得越好的模型,实际能力也越强。
直到昨天。
他用笔记本跑了一个 21GB 的量化模型——阿里的 Qwen3.6-35B-A3B,激活参数才 30 亿。然后把同样的提示词扔给 Anthropic 刚发布的 Claude Opus 4.7——他们的旗舰闭源模型,定价每百万输出 token 75 美元。
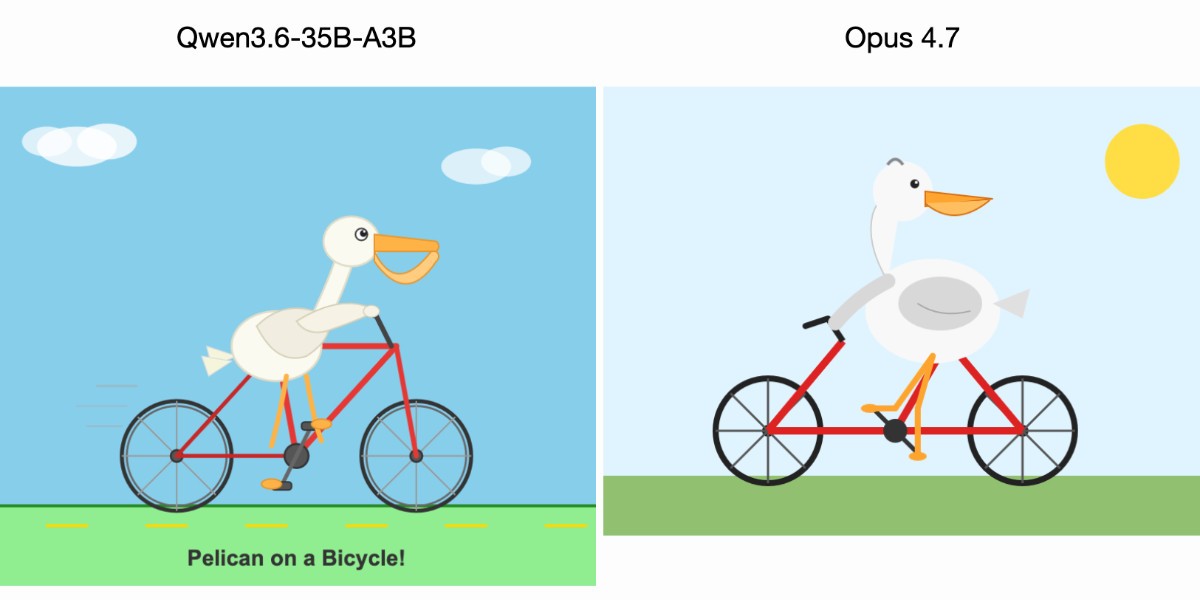
Qwen 画的鹈鹕:自行车框架是对的,天上有云,鹈鹕的喉囊鼓鼓的,地上还写了行字 “Pelican on a Bicycle!”。
Opus 画的鹈鹕:自行车框架是歪的。没有云。鹈鹕回头看,喉囊也不明显。
Simon 不死心,给 Opus 开了 thinking_level: max 再来一次——还是不行,框架歪的方式都不一样。
他又加了一轮测试:火烈鸟骑独轮车。Qwen 的火烈鸟戴墨镜、打领结、叼着烟,SVG 代码里还藏了句注释 <!-- Sunglasses on flamingo! -->。Opus 的火烈鸟中规中矩,用 Simon 的话说——“no flair”。
两轮都是 Qwen 赢。

这条帖子上了 Hacker News 热门,加上 Qwen 官方的发布帖,合计 1,363 分、516 条评论。评论区炸出一个所有人都想问的问题:
如果一个免费的本地模型能画好一只鹈鹕,我还需要为 Opus 付多少钱?
鹈鹕从来不是重点
Section titled “鹈鹕从来不是重点”先说清楚一件事:Simon 自己反复强调,这个测试”obtuse and absurd”——晦涩且荒诞。他不是在说 Qwen 比 Opus 强。他原话是:
“I have enormous respect for Qwen, but I very much doubt that a 21GB quantized version of their latest model is more powerful or useful than Anthropic’s latest proprietary release.”
他不信一个 21GB 的量化版比 Opus 更强。他自己就是 Opus 的重度用户——之前说过 Opus 4.5 是他信任 AI 编码的分界线,写出来的代码他可以直接用,不用改。
那他为什么要写这篇博客?
因为他发现一件有意思的事:这个玩笑测试持续了一年半,一直有一条规律——鹈鹕画得好的模型,整体也好用。直到昨天,这条规律断了。一个跑在笔记本上的小模型,在这个任务上赢了旗舰。但没人会真的认为 Qwen 3.6 比 Opus 4.7 更强。
规律断了,反而是最有价值的发现。
“够用”的天花板
Section titled ““够用”的天花板”这让我想到一个更根本的问题:我们到底在比什么?
Opus 4.7 的定价逻辑建立在一个前提上——强,是稀缺的。稀缺意味着不可替代,不可替代意味着溢价。每百万输出 token 75 美元,你买的不只是能力,你买的是”别的模型做不到”这件事。
但鹈鹕测试揭示了一个裂缝:在相当多的任务上,“别的模型做不到”这个前提正在消失。
不是因为小模型变强了——而是因为很多任务的天花板根本没那么高。
画一只骑自行车的鹈鹕,标准是什么?腿没断、框架对、看着像鹈鹕。这个标准,30 亿激活参数能做到,Opus 也能做到。做到就是做到,做到和做得更好之间没有体感差异。
写一个 CRUD 接口呢?标准是什么?能跑、没 bug、逻辑对。这个标准,很多模型都能达到。
生成一个 SVG 图标?写一段正则表达式?翻译一段技术文档?给函数起个好名字?
这些任务有一个共同特点:它们的”好”有一个上限。到了那个上限,再往上加能力,用户感知不到差别。
就像拧螺丝。电钻比螺丝刀快 10 倍,但如果螺丝只需要拧 5 圈,你用螺丝刀也能拧完。多出来的 10 倍速度,对你没有意义。

三条线同时汇到一点
Section titled “三条线同时汇到一点”为什么是现在?为什么不是去年、不是明年?
2025 年初,开源模型和闭源之间还有代际差距。Llama 2 70B 和 GPT-4、Claude 3 Opus 之间,不是”差不多但便宜”的关系,是”能用”和”好用”的关系。做技术选型的时候,闭源是默认项。
2025 年下半年,DeepSeek-V3、Qwen 2.5 开始在特定 benchmark 上追平闭源。差距缩了,但体感上还是差一档——写代码、画图、复杂推理,闭源的体验明显更好。
到 2026 年 4 月,三条线同时到了:
MoE 架构成熟了。 Qwen3.6-35B-A3B,总参数 350 亿,但每次推理只激活 30 亿。模型可以很大,推理成本可以很低。这不是渐进式改进,是成本结构的根本改变。
量化技术成熟了。 Unsloth 的 UD-Q4_K_S 格式把模型压到 21GB。一台 MacBook Pro M5,一张 RTX 4090,跑得起来。不需要服务器集群,不需要 API 费用,不需要网络延迟。
开源社区的迭代速度成熟了。 Qwen 从 2.5 到 3.6,半年。闭源模型的更新周期是季度,开源的更新周期是月份。阿里的 Qwen 系列在 Hugging Face 上累计下载 7 亿次,超越 Meta 的 Llama,已开源近 400 个模型。这不是一个实验室在闭门造车,是一个全球社区在协同迭代。
三条线汇到一起的结果:一个 21GB 的文件,跑在一台笔记本上,在特定任务上打败了最贵的闭源旗舰。

所以,还要不要为 Opus 付钱?
Section titled “所以,还要不要为 Opus 付钱?”评论区里有人算了一笔账:
Qwen3.6-35B-A3B 量化后约 21GB,MacBook Pro 本地运行,零 API 费用。 Claude Opus 4.7,每百万输出 token 75 美元。
如果你的需求是批量生成 SVG 插图、写 CRUD 接口、翻译文档、做代码补全——本地模型够用,而且免费、零延迟、零隐私风险。
如果你的需求是处理 200 页财报、排查分布式系统故障、做长上下文推理、跑复杂的多步骤 Agent 工作流——Opus 的战场在这里,鹈鹕画得好不好跟这些事没关系。
这不是”开源 vs 闭源”的站队问题。这是一个更实际的问题:你到底需要多强的模型?
大多数日常任务——写代码、改 bug、生成文档、做简单的数据分析——天花板就是”对”。到了那个天花板,本地模型和旗舰模型之间的差距,你感知不到。
少数高难度任务——复杂推理、大规模代码重构、长上下文理解——天花板远高于”对”。在这些场景里,旗舰模型的溢价仍然成立。
Simon 的鹈鹕测试之所以有价值,不是因为它证明了谁比谁强。它证明了一件事:在足够多的任务上,“够用”的标准正在被本地模型击穿。
这对我们意味着什么
Section titled “这对我们意味着什么”作为一个每天用 AI 写代码的人,这件事对我最大的触动不是”开源追上来了”——这个趋势从去年就开始了,不新鲜。
触动在于:选择的逻辑变了。
以前选模型,逻辑是”哪个最强用哪个”。因为强的模型能做到的事,弱的模型做不到。能力差距是代际的。
现在选模型,逻辑应该是”这个任务需要多强”。因为对于大多数任务,能力差距已经不是代际的,是边际的。边际到你用便宜的模型做完,再用贵的模型做一遍,结果差不多。
这不是说旗舰模型没用了。是说旗舰模型的使用场景在收窄——从”默认选项”变成”特殊需求”。
就像你不会用螺丝刀去拆一面墙,但你也不会拿电钻去拧一颗螺丝。工具的价值不在于它有多强,在于它和任务之间的匹配度。

Simon 在博客结尾说了一句挺到位的话:如果你需要的恰好是一只骑自行车的鹈鹕,那现在在笔记本上跑 Qwen 3.6 就是比 Opus 4.7 更好的选择。
这句话听着像是在开玩笑。但仔细想想,它说的是一个正在发生的事实:在足够多的场景里,“够用”已经够了。
你平时用什么模型写代码?有没有试过把旗舰模型换成本地跑的小模型?效果差多少?
Simon Willison. Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7. Simon Willison’s Weblog. https://simonwillison.net/2026/Apr/16/qwen-beats-opus/